
⚠️ Warning: This post is over a year old. The information may be out of date.
Clean Architecture
Tired of your projects getting a mess? Impossible to scale for more features and endpoints? I have a solution to your problems. Today we will explore clean architecture using abstract classes, repository pattern and use cases.
Why Clean Architecture?
Clean architecture is a design approach that emphasizes separation of concerns, agnosticism, and testability, among other principles:
- Modularity, which means that the software is divided into smaller, independent modules. This makes it easier to add new features or modify existing ones without affecting the rest of the system.
- Agnosticism, which means that the software is not tied to any specific technology. This makes it easier to update the technology stack over time, without affecting the rest of the system.
- Separation of concerns, which means that each component of the software has a specific responsibility. This makes it easier to understand and modify the code over time, and reduces the risk of bugs caused by code that tries to do too many things at once.
- Testability, which means that the software is designed to be easy to test. This makes it easier to ensure that the software works correctly, reducing the risk of bugs and making it easier to maintain the code over time.
Repository Pattern
First and foremost, let’s start with a BaseRepository definition, which will be the base of our project.
class ContextManagerRepository(ABC):
@abstractmethod
def commit(self):
...
def __enter__(self):
return self
def __exit__(self, *args, **kwargs) -> None:
self.commit()
class BaseReadOnlyRepository(ABC):
@abstractmethod
def get(self, id: str) -> Optional[BaseEntity]:
...
@abstractmethod
def list(self) -> Iterable[BaseEntity]:
...
class BaseWriteOnlyRepository(ContextManagerRepository):
@abstractmethod
def add(self, other: BaseEntity) -> BaseEntity:
...
@abstractmethod
def remove(self, id: str) -> bool:
...
class BaseRepository(BaseReadOnlyRepository, BaseWriteOnlyRepository, ABC):
...
Code language: CSS (css)Some observations:
- They are all abstract classes with abstract methods, inheriting ABC classes from python’s abc package.
- We are using context manager to commit the changes in case of use of a database that supports it.
BaseRepositoryis a read-and-write base repository; you can also have read-only, for example.
Next, BaseEntity. It only holds an ID field and has two abstract methods from_dict and to_dict for convenience.
@dataclass
class BaseEntity(metaclass=ABCMeta):
id: Optional[str]
@classmethod
@abstractmethod
def from_dict(cls, other: dict):
...
@abstractmethod
def to_dict(self):
...
Code language: CSS (css)Routes
In routes/v1, we have users.py, which contains:
router = APIRouter()
firestore = FirestoreClient()
repo = FirestoreRepository(firestore.collection("users"))
@router.get("/users/")
async def get_users() -> List[UserResponse]:
return [UserResponse.from_orm(e) for e in UserListUseCase(repo).execute()]
@router.post("/users/")
async def create_user(user: UserRequest) -> UserResponse:
entity = UserAddUseCase(repo).execute(user)
return UserResponse.from_orm(entity)
Code language: JavaScript (javascript)We do several things here:
- Creates an APIRouter for routing.
- Creates a FirestoreClient for the repository.
- Defines two routes that make use of the use cases. I’ll talk about the use cases soon.
In main.py include the users’ router to the FastAPI application.
from fastapi import FastAPI
from app.routers.v1 import users as users_v1
app = FastAPI()
app.include_router(users_v1.router, prefix="/v1", tags=["users"])
Code language: JavaScript (javascript)Use Cases
This will be the heart of the application, where all business logic goes on.
Every use case receives a repository as a dependency injection, and has a execute method.
We have two use cases, one for listing users on GET /v1/users/ and another for creating users on POST /v1/users/.
First, we define a BaseUseCase which is a abstract class, for use as base of all other uses cases:
from abc import ABCMeta
from abc import abstractmethod
class BaseUseCase(metaclass=ABCMeta):
@abstractmethod
def execute(self, *args, **kwargs):
...
Code language: JavaScript (javascript)Then we use it on two use cases, one for listing users and another to create. Since we are inheriting the BaseUseCase, we must implement the method execute, it is mandatory:
from app.use_cases import BaseUseCase
class UserListUseCase(BaseUseCase):
repo: BaseRepository
def __init__(self, repo: BaseRepository) -> None:
self.repo = repo
def execute(self) -> Iterable[BaseEntity]:
return self.repo.list()
class UserAddUseCase(BaseUseCase):
repo: BaseRepository
def __init__(self, repo: BaseRepository) -> None:
self.repo = repo
def execute(self, other: BaseModel) -> BaseEntity:
with self.repo as repo:
return repo.add(transform(other))
with self.repo as repo, remember the context manager above? Here we’re using it; when it exits the scope, it will call the commit method from the repository.
Testing
For testing, we have a special repository, which stores the data on memory. Since the use cases accept a BaseRepository as a dependency injection, we can use it.
class MemoryRepository(BaseRepository, ABC):
def __init__(self) -> None:
self.data: list[BaseEntity] = []
def get(self, id: str) -> Optional[BaseEntity]:
return next((e for e in self.data if e.id == id), None)
def list(self) -> Iterable[BaseEntity]:
return self.data
def add(self, other: BaseEntity) -> BaseEntity:
self.data.append(other)
other.id = str(len(self.data))
return other
def remove(self, id: str) -> bool:
self.data = list(filter(lambda e: e.id != id, self.data))
return True
def commit(self) -> None:
...
Let’s write a test for UserAddUseCase use case:
def test_user_add_use_case():
data = {
"name": "test",
"email": "me@test.com",
"avatar": "https://s3.amazon.com/avatar.jpg",
}
repo = MemoryRepository()
case = UserAddUseCase(repo)
user = UserRequest(**data)
result = case.execute(user).to_dict()
assert len(result) == 4
assert result["id"] == "1"
assert result["name"] == data["name"]
assert result["email"] == data["email"]
assert result["avatar"] == data["avatar"]
Code language: JavaScript (javascript)It’s easy and fasts to write tests; we don’t need a separate database only for tests.
Data Transfer Object
In every request we want to validate the input, we’re going to use PyDantic for that.
class UserRequest(BaseModel):
name: str = Field(min_length=3, max_length=64)
email: EmailStr
avatar: HttpUrl
Every PyDantic object must inherit BaseModel for validation. As you can see, we define 3 fields:
name, which accepts strings with lengths between 3 and 64.email, which only accepts valid email addresses, internally makes use of the “email-validator” library.avatar, which only accepts valid URLs.
In case of failure to validate any of the fields above, FastAPI will return error 422 Unprocessable Entity with a JSON body explaining what has gone wrong, for example:
{
"detail": [
{
"loc": [
"body",
"avatar"
],
"msg": "invalid or missing URL scheme",
"type": "value_error.url.scheme"
}
]
}
Code language: JSON / JSON with Comments (json)We can have the same for the response; it is a good practice to have separate entities because they may be slightly different; also, the response object has a special configuration from pydantic, which enable us to use the method from_orm, allowing us to loads data into a model from an arbitrary class. To use it, it is necessary to enable the ORM mode.
class UserResponse(BaseModel):
id: str
name: str = Field(min_length=3, max_length=64)
email: EmailStr
avatar: HttpUrl
class Config:
orm_mode = True
allow_population_by_field_name = True
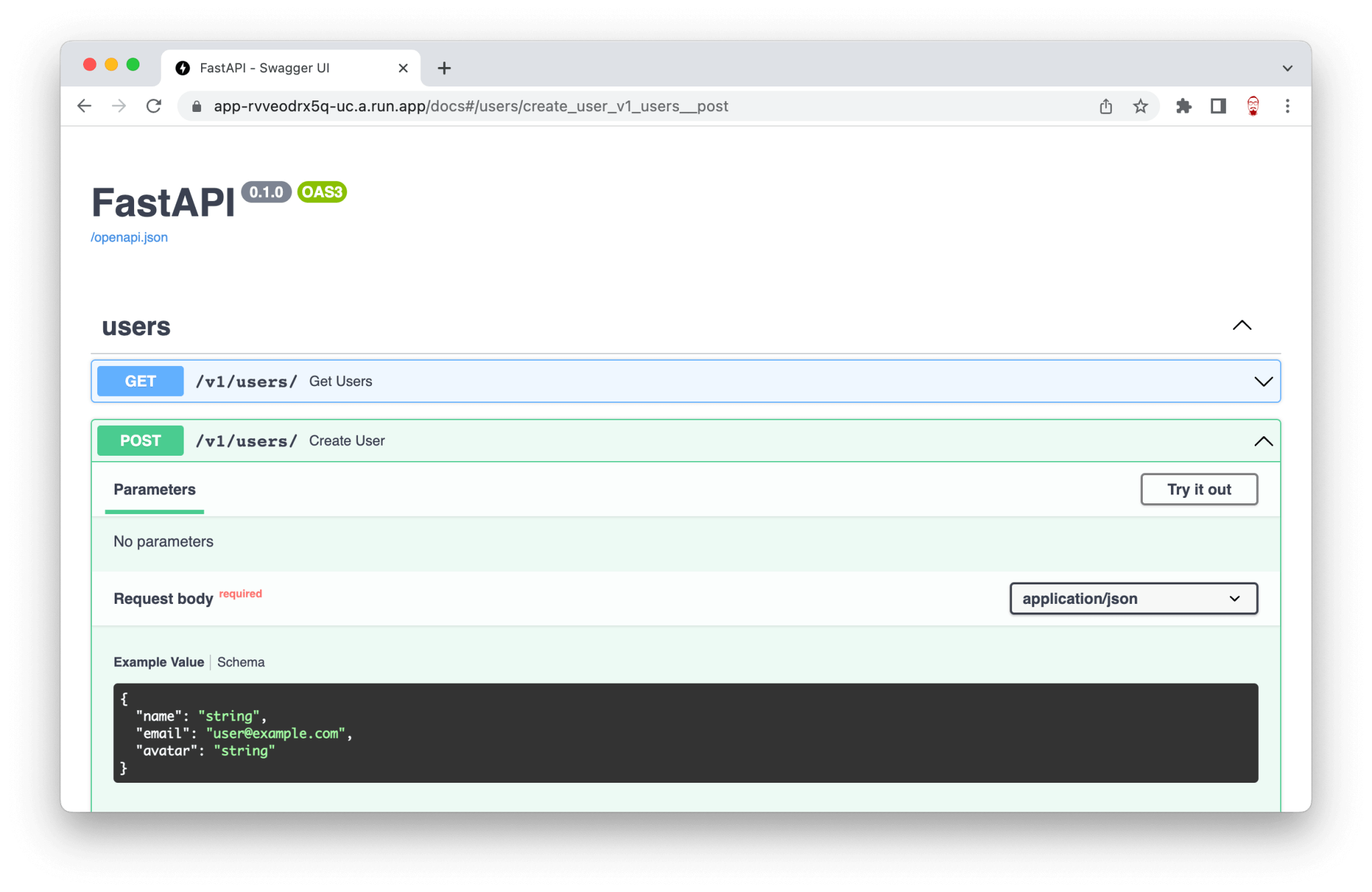
With all this in place, FastAPI can document our request and response on /docs endpoint automatically.
Deploy on Cloud Run
Cloud Run is a serverless solution on the Google Cloud Platform. It scales to zero, has a beefy option of up to 32 GB of RAM and eight vCPUs per instance, and under the hood, runs on top of a managed Kubernetes by Google.
You can deploy anything on it using Docker; there are no limitations!
We use a Dockerfile with multi-stage builds with Poetry for this project. This is enough to run on Run.
FROM python:3.10-slim AS base
ENV PATH /opt/venv/bin:$PATH
ENV PYTHONUNBUFFERED 1
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONFAULTHANDLER 1
FROM base AS builder
WORKDIR /opt
RUN python -m venv venv
RUN pip install poetry
COPY pyproject.toml poetry.lock ./
RUN poetry config virtualenvs.create false
RUN poetry install --no-interaction --no-root --only main
FROM base
WORKDIR /opt
ARG PORT=3000
ENV PORT $PORT
EXPOSE $PORT
ARG options
ENV OPTIONS $options
COPY --from=builder /opt/venv venv
COPY app app
RUN useradd -r user
USER user
CMD exec uvicorn $OPTIONS --host 0.0.0.0 --port $PORT app.main:app
Code language: PHP (php)Bonus
Continuous deployment using GitHub Actions. You will need four secrets set up on GitHub:
GOOGLE_CREDENTIALSit’s a JSON; follow these steps to get it.GCP_PROJECT_IDthe project id that you have chosen.REGIONthe region where you would like to run the service. You can find a list here.SERVICE_NAMEit may be any name that you like.
name: Deploy on Google Cloud Platform
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Authenticate to Google Cloud
uses: google-github-actions/auth@v1
with:
credentials_json: ${{ secrets.GOOGLE_CREDENTIALS }}
- name: Set up Google Cloud SDK
uses: google-github-actions/setup-gcloud@v1
with:
project_id: ${{ secrets.GCP_PROJECT_ID }}
- name: Deploy to Cloud Run
run: |
gcloud config set run/region ${{ secrets.REGION }}
gcloud run deploy ${{ secrets.SERVICE_NAME }} --source $(pwd) --platform managed --allow-unauthenticated
gcloud run services update-traffic ${{ secrets.SERVICE_NAME }} --to-latest
Code language: JavaScript (javascript)Source-code
You can see online here.
The full source code is available here.

