
⚠️ Warning: This post is over a year old. The information may be out of date.
Table of Contents
- Introduction
- A Typical Machine Learning Workflow
- How does Apache Airflow help ?
- The Basics of Airflow
- Building a simple MLOps Pipeline using Airflow
- Other use cases for Airflow
- Conclusion
Introduction
Machine Learning Operations, or MLOps, is an essential aspect of deploying, maintaining, and monitoring machine learning models in production. MLOps is a collaborative function that consists of Data engineers, Machine Learning (ML) engineers, and DevOps engineers. MLOps streamlines the process of deploying machine learning models to production, maintaining and monitoring them, and ensuring that they perform as expected.
In this blog, we will explore how Apache Airflow2, a workflow management tool well suited for MLOps and helps build complex workflow easily.
A Typical Machine Learning Workflow
A Machine Learning workflow usually consists of 3 main stages:
- Data Ingestion and Data Featurization stages of the pipeline, typically handled by Data engineers. The process involves collecting, processing and transforming raw data into a format that is usable by machine learning algorithms. This also includes tasks such as data cleaning, data integration, data transformation, and data storage.
- Model engineering, training, and validation are handled by ML engineers. These tasks involve selecting the appropriate machine learning algorithms, tuning the hyper-parameters of the models, testing and validating the models on data, and making decisions on whether to further tweak the models by retraining them. ML engineers also work closely with data engineers to ensure that the data being used for training and validation is of high quality and relevant to the problem being solved.
- The deployment of ML models to appropriate platforms such as cloud services or on-premises infrastructure is handled by the DevOps team. They also set up monitoring systems to ensure that the application runs smoothly and efficiently, and troubleshoot any issues that arise. They work closely with ML engineers and data scientists to ensure that the model is performing as expected and to make any necessary adjustments.
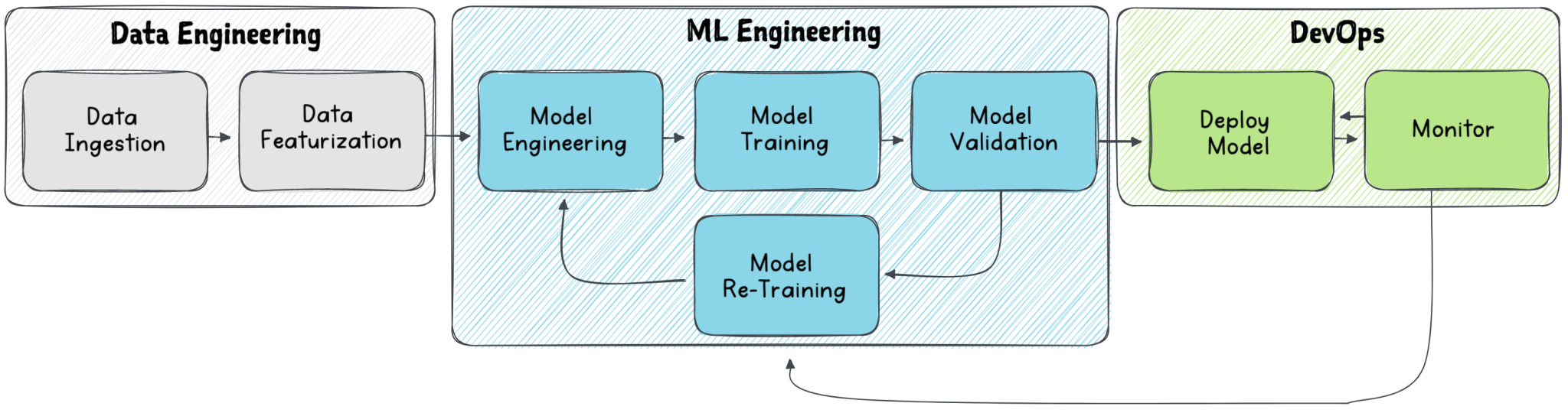
MLOps workflows are complex and involve multiple stages, requiring coordination among various teams of data engineers, ML engineers and DevOps engineers. The technology stack used by the engineering teams can differ significantly. For example, data engineers may use tools like Apache Spark, Kafka, and AWS S3 for data ingestion and processing, while ML engineers may use machine learning libraries such as Scikit-Learn or TensorFlow for model training and validation. DevOps engineers may use technologies like Docker, Kubernetes, and AWS ECS for deploying and monitoring the ML models.
How does Apache Airflow help ?
Apache Airflow is an open-source workflow management tool that allows you to create, schedule, and monitor workflows.
Airflow allows us to describe an MLOps pipeline in code (and in Python), making it an ideal choice for data scientists, ML engineers, and DevOps engineers. Airflow provides a platform to schedule, monitor, and manage complex workflows. Airflow has the following key features:
- Dynamic: Airflow allows users to define workflows as code, making it easy to modify, test and maintain.
- Extensible: Airflow provides a rich set of operators, sensors, and hooks, which can be extended to meet specific needs.
- Scalable: Airflow can orchestrate workflows across multiple nodes, making it possible to manage large-scale workflows.
- Flexible: Airflow integrates with a wide range of tools and technologies, including Kubernetes, Docker and AWS.
The Basics of Airflow
DAG, Task and Operator
Airflow has several key concepts but the main one include DAGs, tasks, and operators.
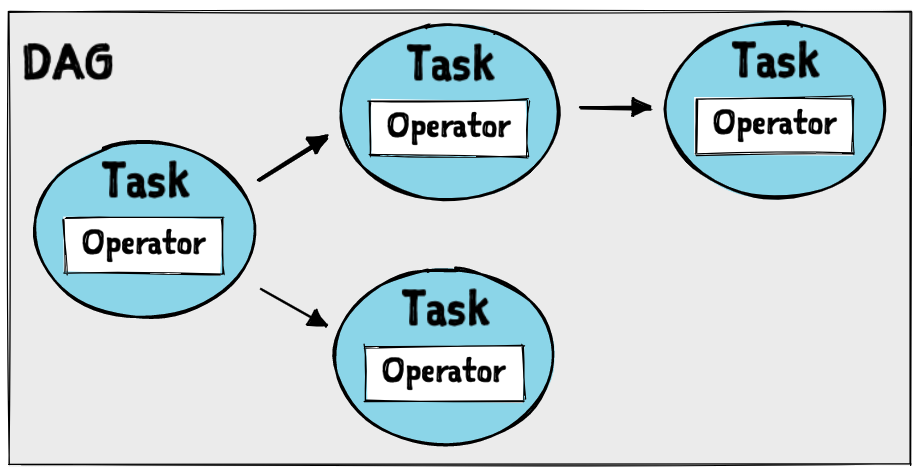
- DAG: Directed Acyclic Graph (DAG), is a collection of tasks with dependencies. The DAG represents the workflow and its dependencies.
- Task: A task is the smallest unit of work that can be executed independently. Each task has a unique ID, a description, and a set of dependencies. The dependencies between tasks are defined using upstream / downstream methods, which specify which tasks must be executed before or after a particular task.
- Operator: An operator is a class that helps execute a task. Airflow provides several built-in operators, including BashOperator, PythonOperator, and EmailOperator.
Architecture of Airflow
Airflow has a modular architecture that comprises six components:
- Web Server: Provides the user interface for Airflow. It allows you to view the status of your DAGs and tasks, and also provides a way to trigger DAG runs manually.
- Scheduler: The scheduler is responsible for executing your DAGs according to their schedules. It queries the metadata database to determine which tasks need to be run and in what order.
- Executor: The executor is responsible for actually running the tasks. The default executor is the SequentialExecutor, which runs tasks sequentially in a single process. Airflow also supports other executors, such as the LocalExecutor, which runs tasks in parallel on the same machine, and the CeleryExecutor, which runs tasks in parallel on a cluster of machines.
- Queue: The queue is used to store the tasks that are waiting to be executed. Each task is added to a queue based on its priority and the resources it requires.
- Worker: The worker is responsible for running the tasks that are assigned to it by the scheduler. Each worker runs in a separate process and can be configured to run on a different machine.
- MetaDataDB: The metadata database stores the state of your DAGs and tasks. It is used by the scheduler to determine which tasks need to be run and in what order.
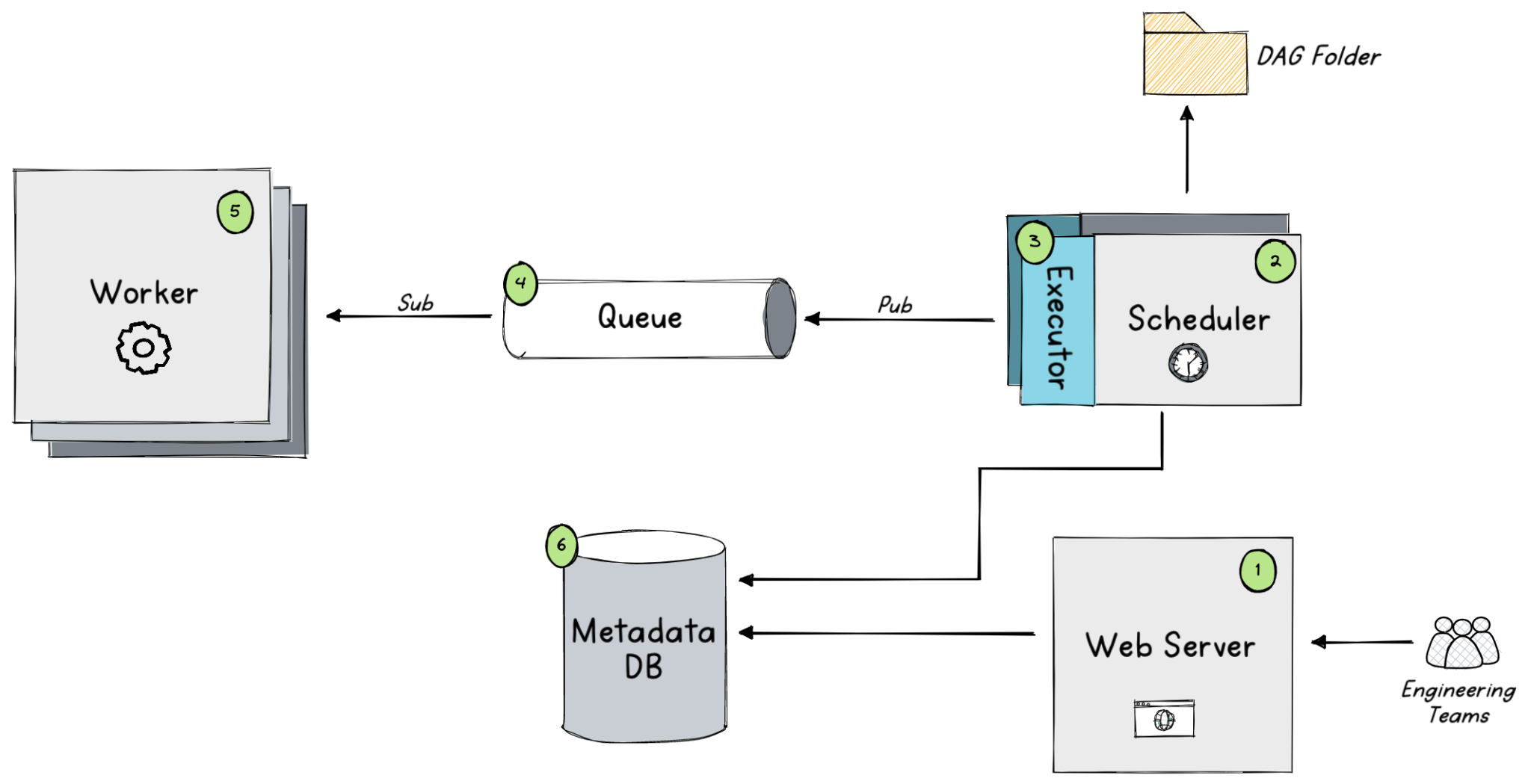
The scheduler runs continuously, and its job is to determine which tasks are ready to run and then places them in the queue. The worker picks up tasks from the queue and executes them. The web-server provides a user interface to view the status of the DAGs and tasks. The executor is responsible for executing the tasks
Building a simple MLOps Pipeline using Airflow
The section walks through an example of a DAG that runs a machine learning pipeline to train and deploy a simple pet detection model, leveraging FastAI algorithm for deep learning and AWS Sagemaker for training the ML model.
Workflow plan
The workflow of the pet detection sample, is depicted below:
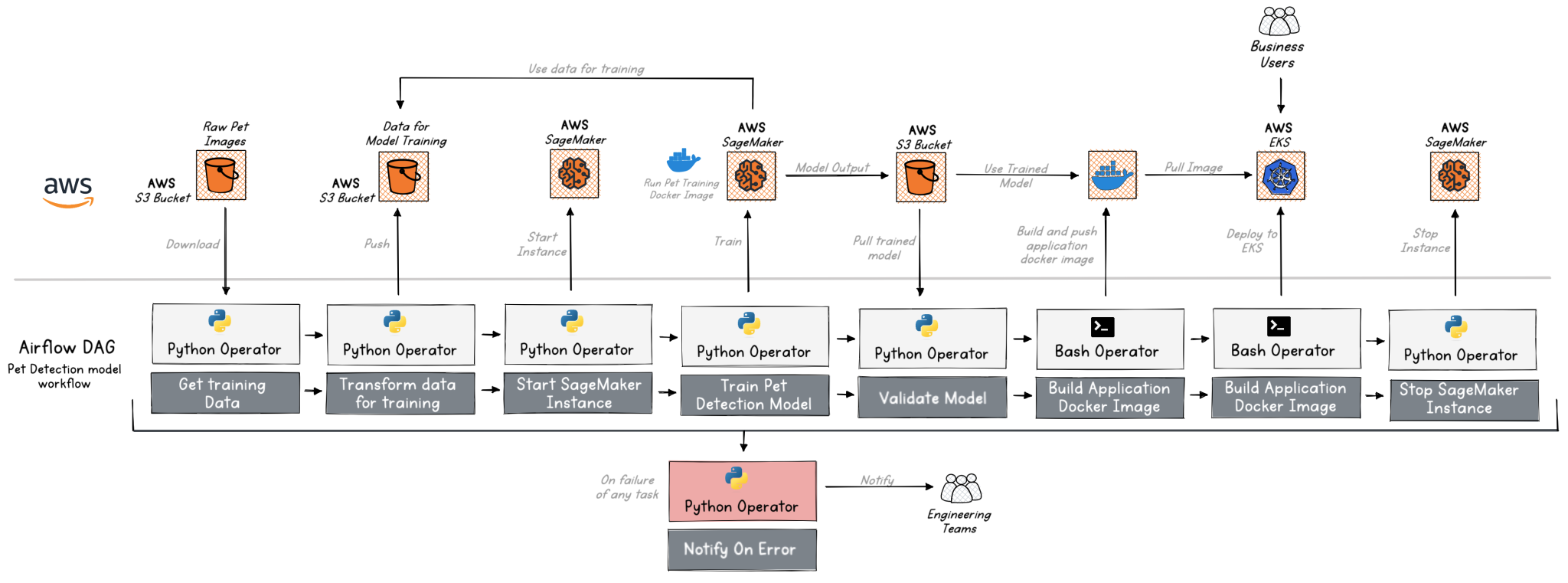
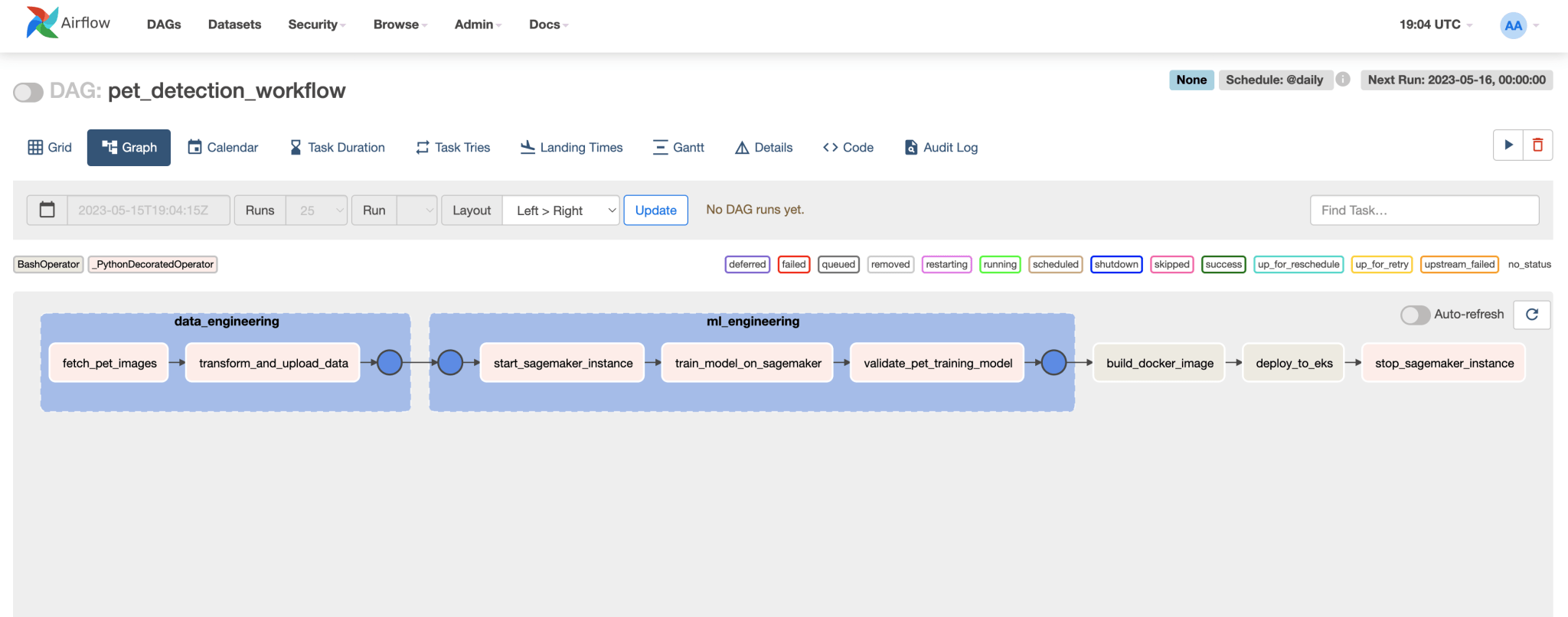
This Airflow workflow consists of several steps to train and deploy a Pet Detection model. Let’s break down the workflow and explain the various Tasks.
- The first step, performed by a PythonOperator, involves fetching the pet images required to train the model. This step retrieves the necessary data from a source.
- The next task uses a PythonOperator to transform and upload the training data to an AWS S3 bucket. This step involves preprocessing or featurizing the data and storing it in a suitable format for training.
- Next task starts the AWS SageMaker instance and waits till its up and running. Sagemaker is an AWS managed service used for training the machine learning model.
- The next task triggered by a PythonOperator, initiates the training of the Pet Detection model on the AWS Sagemaker instance. The training algorithm is represented as a Docker image. Sagemaker pulls the training data from the S3 bucket, trains the model and stores the output in another S3 bucket.
- Next task validates the trained model by running a few tests. This step ensures that the model can accurately detect pets.
- The next two steps are DevOp’s tasks, both executed by a BashOperator. The “Build Application Docker Image” step builds an simple application that exposes a REST endpoint to use the model for detecting if the picture uploaded is a cat / dog. The step builds a Docker image of the Pet Detection Application around the trained ML model. This image encapsulates the model and any necessary dependencies.
- This step on the pipeline is to deploy the Pet Detection Application to AWS EKS (Elastic Kubernetes Service), which provides managed Kubernetes clusters. This step involves launching the application and making it accessible for inference or predictions.
- The final step, stops the AWS SageMaker instance.
In case of any errors encountered during the execution of any task in the workflow, a notification is triggered using the “Notify On Error” task. This notification mechanism helps the stakeholders or responsible parties be aware of any failures or issues in the workflow execution, allowing them to take appropriate actions or perform necessary troubleshooting.
DAG code walkthrough
The workflow above is represented in the DAG below, were all 8 Tasks are programmed. The tasks are connected to each other using the » operator, indicating that it should be triggered after the upstream / previous tasks completes.
import datetime
import pendulum
from airflow.decorators import dag, task, task_group
from airflow.operators.bash import BashOperator
def notify_on_error():
# Task to notify on error
print("Notifying on error...")
@dag(
dag_id="pet_detection_workflow",
schedule_interval="@daily",
start_date=pendulum.now(),
catchup=False,
dagrun_timeout=datetime.timedelta(hours=2),
on_failure_callback=notify_on_error,
tags=["mlops"],
)
def pet_detection_workflow():
@task
def fetch_pet_images():
# PythonOperator to fetch pet images
print("Fetching pet images...")
@task
def transform_and_upload_data():
# PythonOperator to transform and upload data to S3
print("Transforming and uploading data...")
@task
def start_sagemaker_instance():
# PythonOperator to start AWS Sagemaker instance
print("Starting AWS Sagemaker instance...")
@task
def train_model_on_sagemaker():
# PythonOperator to train the model on Sagemaker
print("Training model on Sagemaker...")
@task
def validate_pet_training_model():
# PythonOperator to validate the model
print("Validating model...")
# BashOperator to build Docker Image
build_docker_image = BashOperator(
task_id='build_docker_image',
bash_command='docker build -t pet-detection-app:latest ./pet_detector_app/Dockerfile',
)
# BashOperator to Deploy to EKS
deploy_to_eks = BashOperator(
task_id='deploy_to_eks',
bash_command='kubectl apply -f ./pet_detector_app/kubernetes_manifests',
)
@task
def stop_sagemaker_instance():
# PythonOperator to stop AWS Sagemaker instance
print("Stopping AWS Sagemaker instance...")
@task_group
def data_engineering():
fetch_pet_images() >> transform_and_upload_data()
@task_group
def ml_engineering():
start_sagemaker_instance() >> train_model_on_sagemaker() >> validate_pet_training_model()
data_engineering() >> ml_engineering() >> build_docker_image >> deploy_to_eks >> stop_sagemaker_instance()
pet_ml_ol = pet_detection_workflow()
Code language: PHP (php)Once the DAG has been loaded, the Web-Server will display all the pet_detection_workflow workflow.
All the tasks on the DAG can be viewed by access the graph on the page.
Lets quickly walkthrough some of the critical implementations to give a general idea of each of the tasks. For S3 Bucket and AWS SageMaker interactions we can use the Boto3 library.
import boto3
from datetime import datetime
from airflow.models import Variable
sagemaker_client = boto3.client('sagemaker')
# Start SageMaker Instance
def start_sagemaker_instance():
print("Starting SageMaker training job...")
# Set up SageMaker training job parameters
role_arn = Variable.get('AWS_SAGE_MAKE_ROLE_ARN')
instance_type = Variable.get('AWS_SAGE_MAKE_INSTANCE_TYPE')
spot_instance = True
max_wait_time = 72000 # Number of seconds to wait for the job to complete
job_name = 'pet-detection-training-job-' + datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
output_location = 's3://{}/{}'.format(Variable.get('PET_DETECTION_OUTPUT_S3_BUCKET'), job_name)
input_location = 's3://{}/{}'.format(Variable.get('PET_DETECTION_INPUT_S3_BUCKET'), "pet_detector_data")
training_image = Variable.get('AWS_ECR_PET_DETECTION_TRAINING_IMAGE')
# Set up the training job
training_job = {
'AlgorithmSpecification': {
'TrainingImage': training_image,
'TrainingInputMode': 'File',
},
'RoleArn': role_arn,
'OutputDataConfig': {
'S3OutputPath': output_location,
},
'ResourceConfig': {
'InstanceCount': 1,
'InstanceType': instance_type,
'VolumeSizeInGB': 10,
},
'StoppingCondition': {
'MaxWaitTimeInSeconds': max_wait_time,
},
'TrainingJobName': job_name,
'HyperParameters': {
'epochs': '10',
'batch-size': '32',
},
'InputDataConfig': [
{
'ChannelName': 'training',
'DataSource': {
'S3DataSource': {
'S3DataDistributionType': 'FullyReplicated',
'S3DataType': 'S3Prefix',
'S3Uri': input_location,
},
},
'ContentType': 'application/x-image',
'RecordWrapperType': 'None',
'CompressionType': 'None'
}
]
}
# Start the training job
response = sagemaker_client.create_training_job(**training_job)
print("SageMaker training job started with name: " + job_name)
# Wait till SageMaker Instance is running
check_sagemaker_status(job_name)
return job_name
# Start SageMaker Instance
def check_sagemaker_status(training_job_name):
while True:
try:
response = sagemaker_client.describe_training_job(TrainingJobName=training_job_name)
status = response['TrainingJobStatus']
print(f"SageMaker training job status: {status}")
if status in ['Completed', 'Failed', 'Stopped']:
break
time.sleep(30)
except ClientError as e:
if e.response['Error']['Code'] == 'ResourceNotFound':
print(f"Training job {training_job_name} not found")
else:
print(f"Error getting training job status: {e}")
# Stop SageMaker Instance
def stop_sagemaker_instance(training_job_name):
try:
response = sagemaker_client.describe_training_job(TrainingJobName=job_name)
instance_name = response['TrainingJobName']
sagemaker_client.stop_training_job(TrainingJobName=instance_name)
print(f"SageMaker instance '{instance_name}' stopped successfully.")
except ClientError as e:
if e.response['Error']['Code'] == 'ResourceNotFound':
print(f"SageMaker instance '{job_name}' not found.")
else:
print(f"Error stopping SageMaker instance: {e}")
Code language: PHP (php)On the critical parts of the ML code to Train and Validate we leverage the FastAI library. If you notice above the AWS SageMaker is provided with a training_image docker image, this image consists of the application that helps train the ML model using the FastAI library. In can be implementation as
import boto3
from io import BytesIO
from fastai.vision import *
import tarfile
import os
# Define the S3 bucket and prefix to load the data from
S3_BUCKET = ${S3_BUCKET}
S3_PREFIX = "pet_detector_data"
# Define the path to the model file
MODEL_PATH = "/opt/program/model"
# Download the training data from S3 and extract it
s3 = boto3.client("s3")
response = s3.list_objects_v2(Bucket=S3_BUCKET, Prefix=S3_PREFIX)
for obj in response.get("Contents", []):
key = obj["Key"]
if key.endswith(".tar.gz"):
s3.download_file(S3_BUCKET, key, "/tmp/data.tar.gz")
tar = tarfile.open("/tmp/data.tar.gz", "r:gz")
tar.extractall("/tmp/data")
tar.close()
# Define the path to the training data
train_path = "/tmp/data/train"
# Load the images
tfms = get_transforms(do_flip=False)
data = ImageDataBunch.from_folder(
path=train_path,
valid_pct=0.2,
ds_tfms=tfms,
size=224,
bs=32,
).normalize(imagenet_stats)
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
# Train the model
learn.fit_one_cycle(4)
# Save the trained model
os.makedirs(os.path.dirname(MODEL_PATH), exist_ok=True)
learn.export(MODEL_PATH)
Code language: PHP (php)In the code above the training data is loaded from an S3 bucket. Finally, the trained model is saved to /opt/program/model, which is the path expected by the SageMaker endpoint. This output file is pushed by SageMaker to the Output S3 Bucket.
To use the model trained on SageMaker, we can expose an API around the model with:
from fastai.vision.all import *
from flask import Flask, request, jsonify
app = Flask(__name__)
# Download Model from S3 on Start up and save it to a Path
learn_inf = load_learner('/opt/models/export.pkl')
# Endpoint to Predict the pet, for an image uploaded
@app.route('/predict', methods=['POST'])
def predict():
img_file = request.files['image']
img = PILImage.create(img_file)
# Use the trained model to predit
pred, _, prob = learn_inf.predict(img)
print(str(prob))
# Send the response back
return jsonify({'prediction': str(pred), 'prob': str(prob)})
if __name__ == '__main__':
app.run(debug=True)
Code language: PHP (php)Other use cases for Airflow
Apart from MLOps, there are other use cases where Apache Airflow can be used for example:
Payment processing: Airflow can be used to automate payment processing tasks such as sending invoices, processing payments, and reconciling accounts.
Fraud detection: Airflow can be used to automate fraud detection tasks such as monitoring transactions for suspicious activity, flagging unusual transactions for review, and generating alerts for potential fraud.
Customer engagement: Airflow can be used to automate customer engagement tasks such as sending personalized emails, generating targeted offers, and tracking customer interactions.
There are also proven use cases from Fortune 500 companies that have used Apache Airflow for automating workflows and managing dependencies
Conclusion
In conclusion, Apache Airflow2 is a powerful tool for managing dependencies and automating workflows. It is well suited for MLOps, where machine learning workflows need to be repeatable and automated. To make adoption of Airflow simpler the 3 major cloud providers have a fully managed Airflow services [Amazon Managed Workflows for Apache Airflow , Azure Managed Airflow and Google Cloud Composer].

