
⚠️ Warning: This post is over a year old. The information may be out of date.
As you know, a single core inside CPU can process only one instruction at a time. But in reality, a typical program performs multiple tasks, and if it has to wait for one task to complete before starting the next one, you’ll be sitting around for a long time to get anything done. There are some smart ways to get things done from the a single CPU that feels multiple things are getting done simultaneous while in reality they are not!
At the core of this smart strategy is that all the tasks doesn’t require the use of CPU all the time. Many times CPU waits for tasks to be finished by another hardware before it can move ahead. For example, writing to disk, reading data from network, etc.
Let’s first understand some key terminologies to make our life easier.
Concurrency & Parallelism
This ability of a program to deal with multiple things simultaneously is what we call concurrency. This mechanism allows an OS to run thousands of processes on a machine with only a few cores. If multiple tasks run at the same physical time, as in the case of a multi-core machine or a cluster, then we have parallelism, a particular type of concurrency.
To understand the difference, let’s take an example of 20 people placing orders at a cafe. Assume the time taken to place one order equals the time to prepare an order (say T minutes).
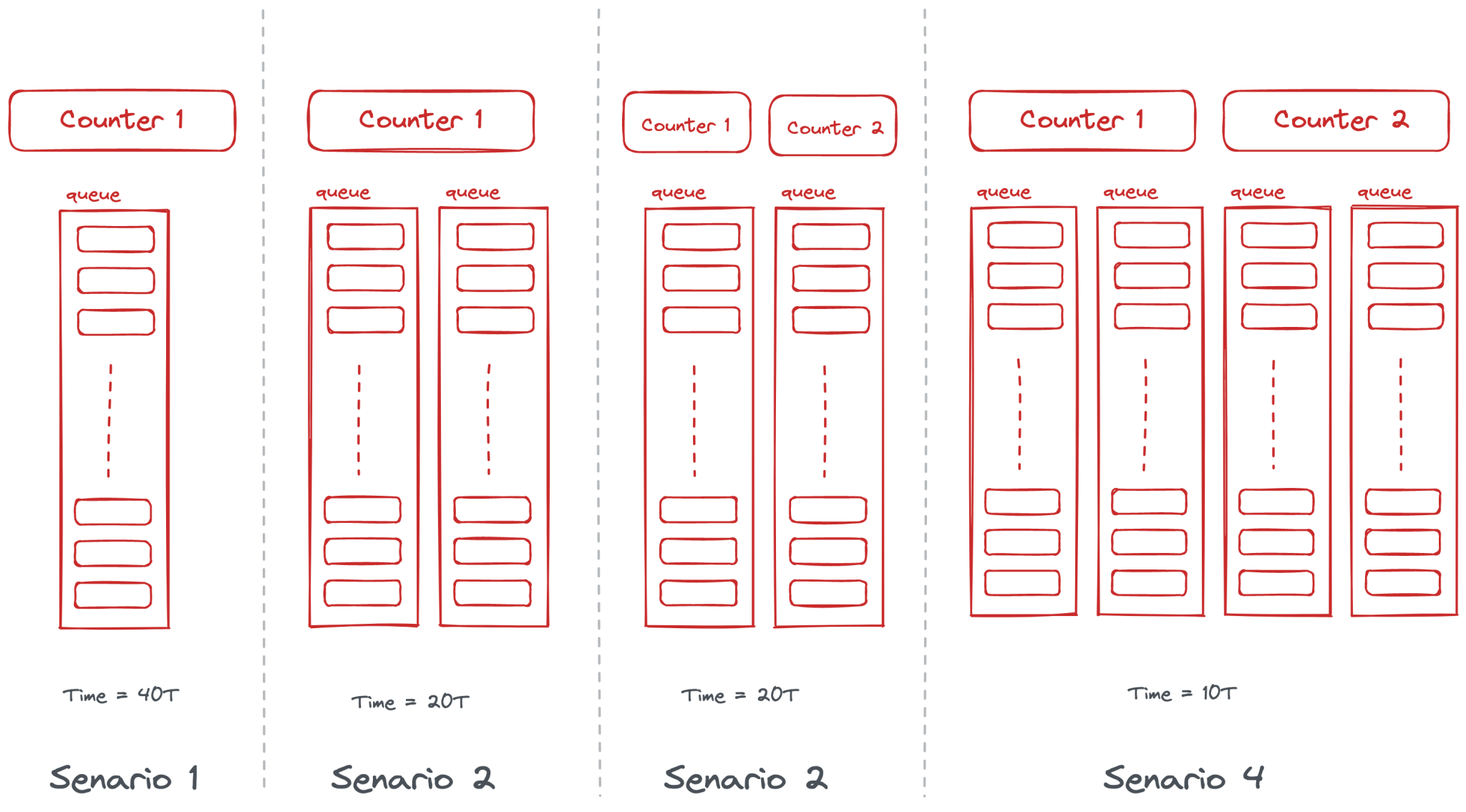
- 1 Counter – 1 Queue: In the sequential version, while the first order is being prepared, the counter is idle. Total time 40T (20 x 2T)
- 1 Counter – 2 Queues: The concurrent way would be to have two queues (say A and B) placing orders alternatively. In this case, the counter will take the first order from queue A, and while that order is being prepared, the counter will take the second order from queue B. Total time 20T (10 x 2T)
- 2 Counters – 2 Queues: In parallelism, both queues can place orders simultaneously. But each counter is still processing its queue sequentially. Note that even after doubling resources, there’s not much performance improvement. Total time 20T (20 x T)
- 2 Counters – 4 Queues: This is parallel as well as concurrent and the most efficient way. Total time 10T (10xT)
In the context of computers, we can think of each core in the CPU as an ordering counter and threads as queues. When waiting for resources, the core switches context between threads and this is called concurrent processing.
To see how one goes from concurrency to async/await, we’ll take an example of a chat server – a program that is supposed to handle multiple clients simultaneously.
- Sequential version: This version of the server is not concurrent by design. When multiple clients try to connect to the server at about the same time, one client connects and occupies the server while other clients wait until the current client disconnects.
- Make it concurrent using OS threads (we’ll also see how these don’t scale well):
- The one-thread-per-client approach is the easiest to implement; here, when n clients try to connect to the server, n threads will be used. But threads are an expensive resource in terms of memory, so you can’t have too many of them.
- Thread pools solve the problem of uncontrolled thread creation. Instead of submitting each task to a separate thread, we submit tasks to a queue and let a group of threads, called a thread pool, take and process the tasks from the queue. This approach looks simple and practical, but if slow clients keep the threadpool occupied, new clients won’t be able to connect.
- Concurrent version that runs in a single thread:
- I/O multiplexing: The better approach is to ask the OS which sockets are ready for reading and writing. This version of the server handles multiple clients perfectly fine. Its main disadvantage compared to the multi-threaded versions is that writing to a socket may block if the write queue is full, so we should also check whether the socket is ready for writing. Of course, this brings in a lot of management overhead.
- Concurrent using Async IO: The asyncio (introduced in 2012, see PEP-3156) provides a powerful loop class, which our programs can submit prepared tasks, called coroutines, to, for asynchronous execution. The event loop handles the scheduling of the tasks and optimization of performance around blocking I/O calls. This would allow our chat server to be available for new clients to connect, even while waiting for connected clients to send messages.
Async IO event loop does not maintain a queue of scheduled coroutines, but is based on callbacks, and the coroutine support is implemented on top of that by providing methods to schedule and run coroutines. These coroutines do not yield messages to the event loop but yield futures. A Future instance represents the result of some operation that may not be available yet. When a coroutine yields a future, it tells the event loop: “I’m waiting for this result. It may not be available yet, so I’m yielding the control. Wake me up when the result becomes available”.
Async in Python
Async in python seems very promising, but it could be very painful if not used carefully. Unless 100% of the libraries you want support async. you will get stuck on some sync library. Although the async ecosystem is improving every year, it’s still a second class citizen.
Async IO takes long waiting periods in which functions would otherwise be blocking and allows other functions to run during that downtime.
Consider a classic async IO example of a Hello World program which goes a long way towards illustrating its core functionality
#!/usr/bin/env python3
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
if __name__ == "__main__":
import time
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"File executed in {elapsed:0.2f} seconds.")
Code language: JavaScript (javascript)When you execute this file
One
One
One
Two
Two
Two
File executed in 1.01 seconds.
Code language: CSS (css)The order of this output is the heart of async IO. Talking to each of the calls to count() is a single event-loop, or coordinator. When each task reaches await asyncio.sleep(1), the function yells up to the event loop and gives control back to it, saying, “I’m going to be sleeping for 1 second. Go ahead and let something else meaningful be done in the meantime.”
Contrast this to the synchronous version:
#!/usr/bin/env python3
import time
def count():
print("One")
time.sleep(1)
print("Two")
def main():
for _ in range(3):
count()
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"File executed in {elapsed:0.2f} seconds.")
Code language: PHP (php)When executed yield
One
Two
One
Two
One
Two
File executed in 3.01 seconds.
Code language: CSS (css)While using time.sleep() and asyncio.sleep() may seem banal, they are used as stand-ins for any time-intensive processes that involve wait time. That is time.sleep() can represent any time-consuming blocking function call, while asyncio.sleep() is used to stand in for a non-blocking call.
Summary
We learned Async IO is a mechanism for running multiple I/O operations simultaneously without using a lot of computer memory, allowing for faster execution of programs. It uses an event loop to manage tasks and coroutines to yield futures, representing the result of an operation that may not be available yet. Async IO is useful for tasks that involve long waiting periods, such as network requests, and can be implemented in Python using the asyncio library.

